
티스토리 뷰
SQL을 사용할 때 연관관계가 있는 다른 테이블의 정보를 이용하려고 한다면 JOIN을 사용해야 합니다. INNER JOIN, OUTER JOIN과 같은 JOIN 형태가 존재합니다. 그렇다면 FETCH JOIN은 무엇을 의미할까요?
Fetch Join
페치 조인은 SQL에서 이야기하는 조인의 종류는 아닙니다. JPQL에서 성능 최적화를 위해 제공하는 조인의 종류입니다. 이를 설명하기 전에 JPQL에 대해 간략히 설명하겠습니다.
JPQL(Java Persistence Query Language)
SQL이 DB에 있는 테이블을 조회하는 쿼리라고 한다면 JPQL은 엔티티 객체를 조회하는 객체지향 쿼리를 의미합니다. 문법은 SQL과 비슷하고 SQL이 제공하는 기능을 유사하게 지원합니다.
public class Main {
public static void main(String[] args) {
// 중략
try {
// 중략
// 쿼리 생성
String query = "select b from Book b where b.name = '해리포터'";
List<Book> books = em.createQuery(query, Book.class)
.getResultList();
for (Book book : books) {
System.out.println("book.id = " + book.getId());
System.out.println("book.name = " + book.getName());
}
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}위 코드를 보시면 SQL 문법과 비슷한 형태로 쿼리를 생성하는 것을 확인할 수 있습니다. JPQL은 SQL을 추상화하였기에 특정 데이터베이스에 의존하지 않고 데이터베이스 방언만 변경하면 JPQL을 수정하지 않고 자연스럽게 데이터베이스를 변경할 수 있습니다. 또한 JPQL은 엔티티 직접 조회, 묵시적 조인, 다형성 지원 등의 기능을 제공하기에 SQL보다 간결하다는 장점을 가지고 있습니다.
페치 조인
이제 페치 조인에 대해 알아보도록 하겠습니다. 앞서 말씀드렸다시피 JPQL에서 성능 최적화를 위해 제공하는 기능으로 연관된 엔티티나 컬렉션을 한 번에 같이 조회할 수 있는 기능입니다. JOIN FETCH 명령어로 사용할 수 있습니다.
등장 배경
JPA는 2가지 페치 전략이 존재하는데 기본적으로 지연 로딩 전략을 사용하게 됩니다. 이에 대해 조금 더 알고 싶은 분은 아래의 글을 참고해주시기 바랍니다.
[JPA] 프록시와 로딩 전략
프록시 는 무엇을 의미할까요? 이 질문에 앞서 프록시가 등장하게 된 배경에 대해 먼저 알아보도록 하겠습니다. Proxy 등장 배경 객체는 객체 그래프로 연관된 객체들을 자유롭게 탐색할 수 있습
woo-chang.tistory.com
Library libraryA = new Library();
libraryA.setName("libraryA");
em.persist(libraryA);
Library libraryB = new Library();
libraryB.setName("libraryB");
em.persist(libraryB);
Library libraryC = new Library();
libraryC.setName("libraryC");
em.persist(libraryC);
Book bookA = new Book();
bookA.setName("bookA");
bookA.setLibrary(libraryA);
em.persist(bookA);
Book bookB = new Book();
bookB.setName("bookB");
bookB.setLibrary(libraryB);
em.persist(bookB);
Book bookC = new Book();
bookC.setName("bookC");
bookC.setLibrary(libraryC);
em.persist(bookC);
String query = "select b from Book b";
em.flush();
em.clear();
List<Book> books = em.createQuery(query, Book.class).getResultList();
for (Book book : books) {
System.out.println(book.getLibrary());
}지연 로딩 전략으로 인해 다음과 같은 코드가 작성되었을 때 조회된 Book의 개수만큼 추가로 Library를 조회하는 쿼리가 나가게 됩니다. 이러한 문제는 N+1 문제라고 합니다. 처음 조회부터 조인시켜 데이터를 가져올 수 있게 하려고 페치 조인이 등장하게 되었습니다.
그렇다면 일반 조인을 사용하면 되지 않을까 하는 의문이 생길 수 있습니다. 일반 조인과 차이점은 일반 조인 실행 시 연관된 엔티티를 함께 조회하지 않습니다. 조인은 하지만 데이터가 조회되지 않는다는 의미입니다. 그렇기에 위와 마찬가지로 N+1 문제가 발생합니다.
엔티티 페치 조인
제가 작성한 예제에서는 Library와 Book의 연관관계가 1:N으로 지정되어있습니다. 페치 조인을 사용해서 Book 엔티티를 조회하면서 Library 엔티티도 함께 조회하는 예제를 살펴보도록 하겠습니다.
String query = "select b from Book b join fetch b.library";
em.flush();
em.clear();
List<Book> books = em.createQuery(query, Book.class).getResultList();
for (Book book : books) {
System.out.println(book.getLibrary());
}JOIN FETCH 명령어를 사용하여 Book의 Library를 함께 조회합니다. 실제 쿼리문에서도 JOIN 쿼리가 나가게 되고 데이터가 함께 조회되기에 추가적인 쿼리가 나가지 않습니다. JPQL의 일반적인 조인과 다르게 b.library의 별칭이 존재하지 않는데 페치 조인은 별칭을 사용할 수 없습니다. (하이버네이트는 페치 조인에도 별칭을 허용합니다.)
페치 조인을 사용하였기에 Book과 Library가 객체 그래프를 유지하면서 데이터를 조회할 수 있습니다. Library는 프록시가 아닌 실제 엔티티이므로 Book 엔티티가 영속성 컨텍스트에서 분리되어 준영속 상태가 되어도 연관된 Library를 조회할 수 있습니다.
컬렉션 페치 조인
이제는 Library에서 Book을 페치 조인해보도록 하겠습니다.
String query = "select l from Library l join fetch l.books where l.name = 'libraryA'";
em.flush();
em.clear();
Library library = em.createQuery(query, Library.class).getSingleResult();
for (Book book : library.getBooks()) {
System.out.println(book.getName());
}Library를 조회하면서 페치 조인을 사용하여 연관된 Book 컬렉션도 함께 조회됩니다.
페치 조인과 DISTINCT
Library libraryA = new Library();
libraryA.setName("libraryA");
em.persist(libraryA);
Book bookA = new Book();
bookA.setName("bookA");
bookA.setLibrary(libraryA);
em.persist(bookA);
Book bookB = new Book();
bookB.setName("bookB");
bookB.setLibrary(libraryA);
em.persist(bookB);
String query = "select l from Library l join fetch l.books where l.name = 'libraryA'";
em.flush();
em.clear();
List<Library> libraries = em.createQuery(query, Library.class).getResultList();
for (Library library : libraries) {
System.out.println("library.name = " + library.getName() + ", book count = " + library.getBooks().size());
}페치 조인에 대해 알아보았으니 다음 코드의 결과가 예측되시나요? 출력 결과는 한 줄이고 libraryA에 대한 Book 개수는 2로 다들 예상할 것으로 생각합니다. 하지만 결과는 그렇지 않습니다. 결과는 아래와 같이 출력됩니다.

왜 이런 결과가 나오게 되었을까요? 지금부터 그림을 통해 설명해 드리도록 하겠습니다. 컬렉션 페치 조인을 시도하게 되면 다음과 같은 그림으로 조인을 시도합니다.
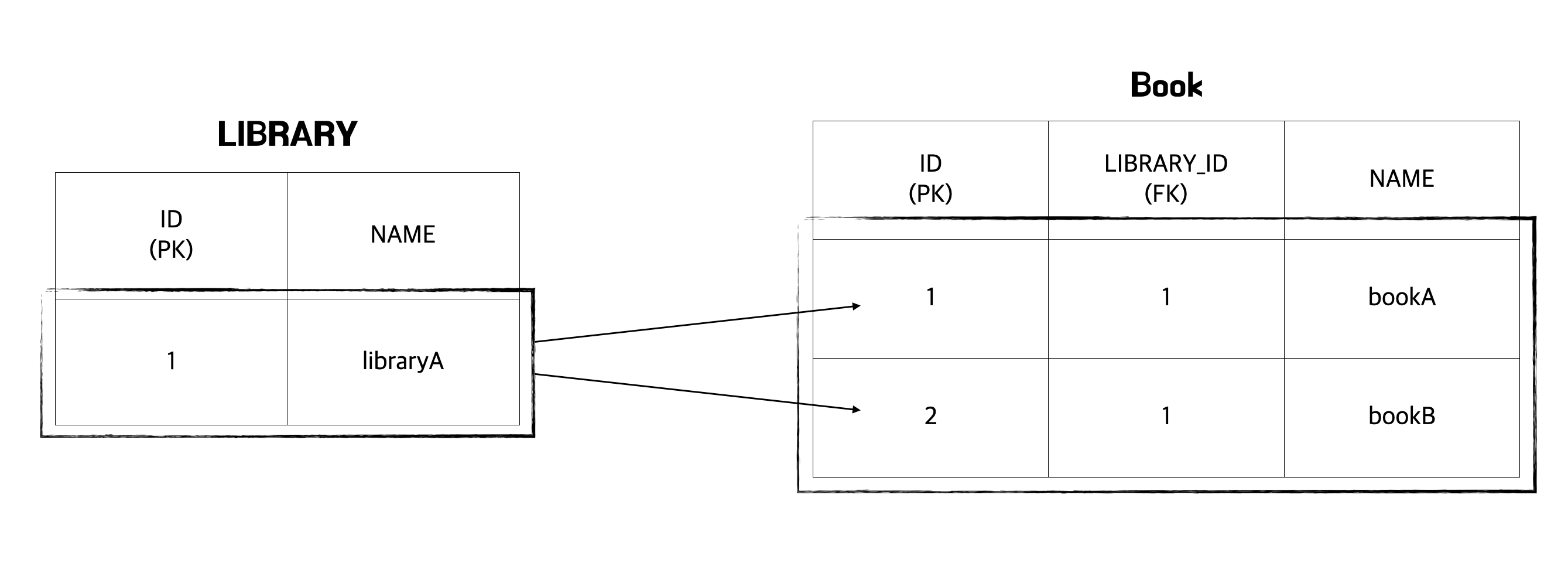
컬렉션 페치 조인 결과 테이블은 아래와 같습니다.
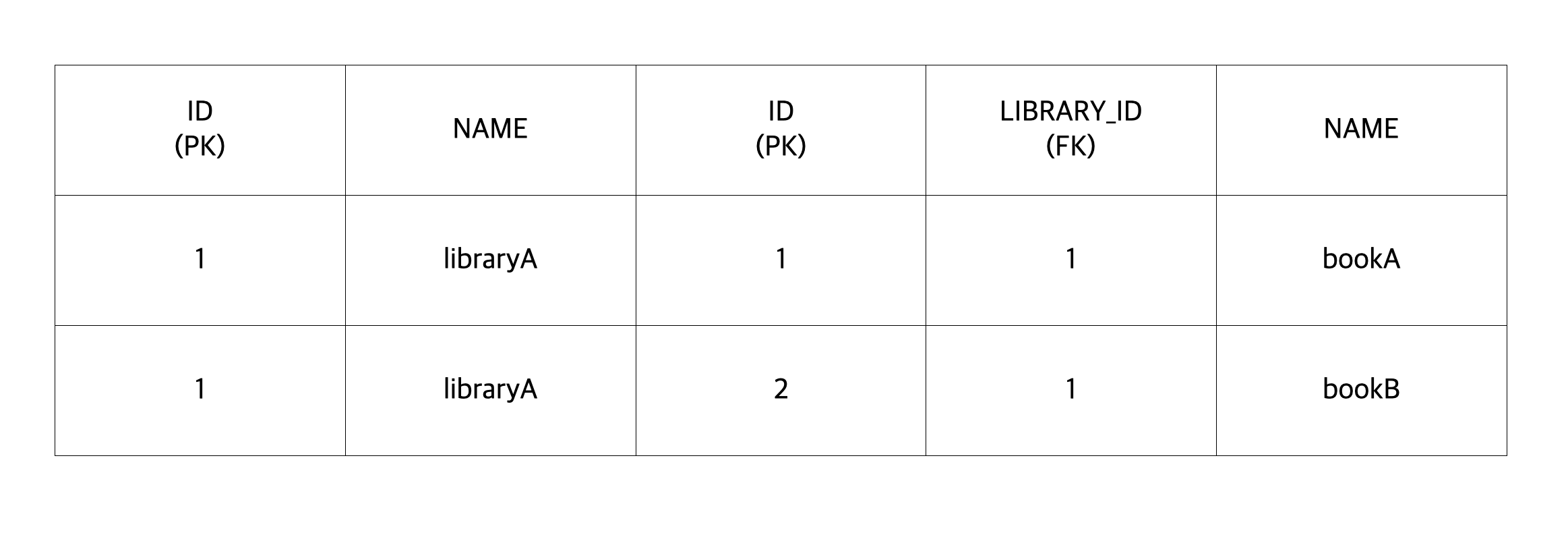
컬렉션 페치 조인 결과 객체는 다음과 같은 형태를 보이게 됩니다.
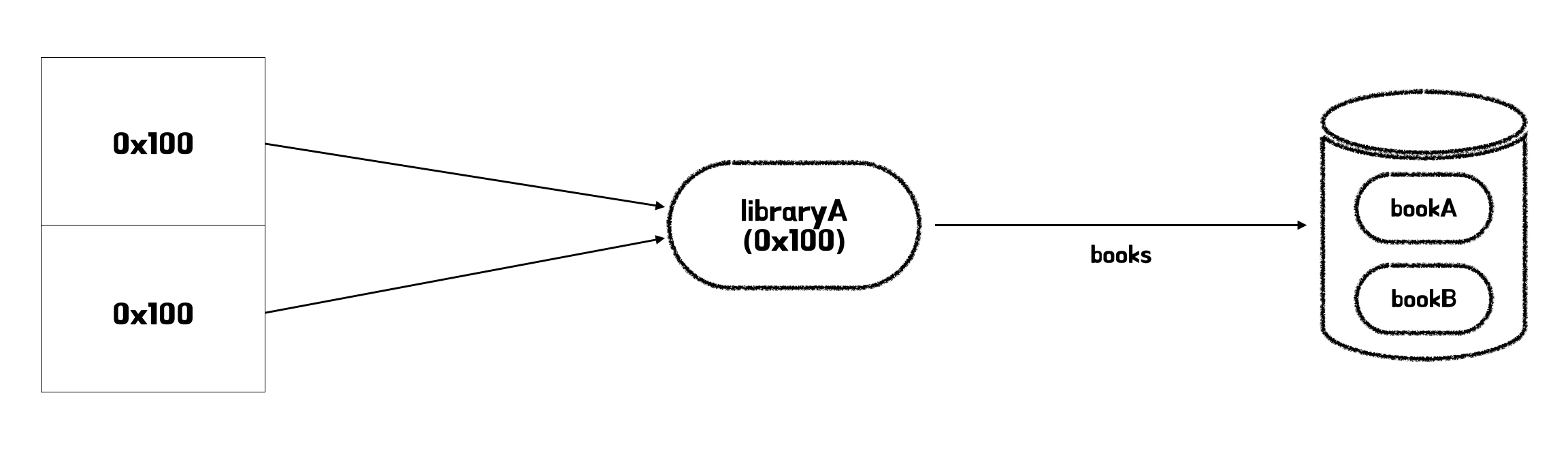
이제 예상과 다른 결과가 나오게 된 배경이 이해되시나요? 연관된 Book 데이터가 같이 조회되기 때문에 결과가 증가해서 위와 같은 결과가 나오게 되는 것입니다. 일대다 조인에서는 증가한 결과가 나올 수 있지만 일대일, 다대일 조인에서는 결과가 증가하지 않습니다. 조인했을 때 익숙한 결과를 얻기 위해서는 DISTINCT를 사용하면 됩니다.
String query = "select distinct l from Library l join fetch l.books where l.name = 'libraryA'";DISTINCT는 SQL에서 중복을 제거하는 명령어입니다. JPQL에서의 DISTINCT 명령어는 SQL에 DISTINCT 명령어를 추가하는 것과 동시에 애플리케이션 상에서 중복을 제거하는 동작도 수행합니다. 따라서 SQL 결과에서는 위와 같은 결과 테이블을 반환하지만, 애플리케이션에서는 중복된 데이터가 걸러집니다. 즉, 0x100을 가리키는 포인터가 하나가 됨을 의미합니다.
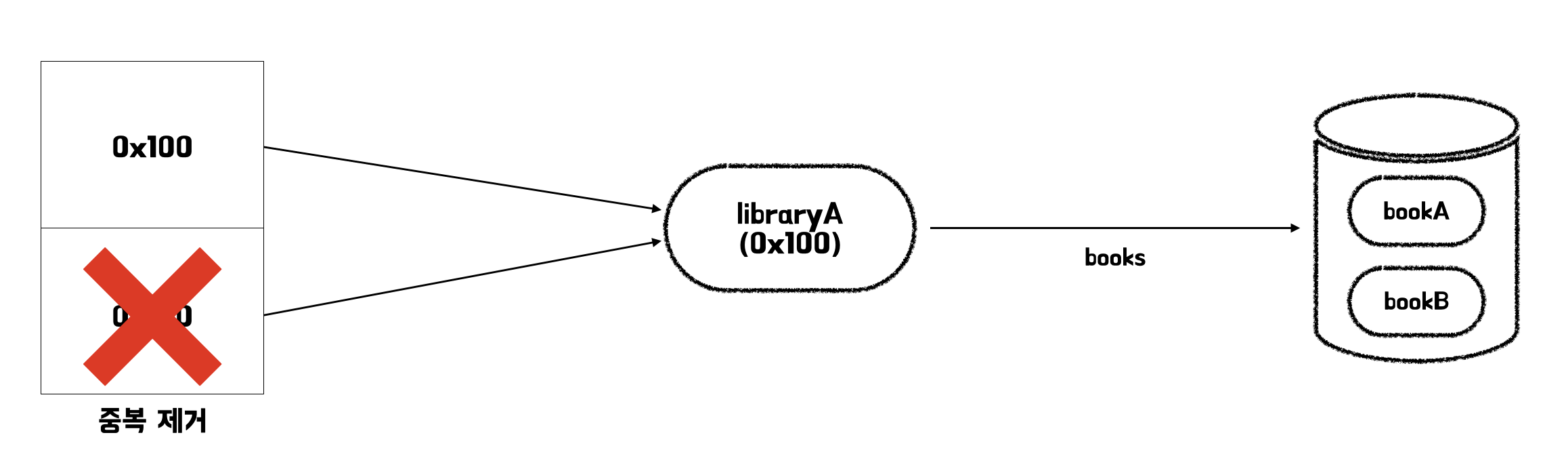
페치 조인의 특징과 한계
특징
페치 타입 설정과 같이 엔티티에 직접 적용하는 로딩 전략은 애플리케이션 전체에 영향을 미치므로 글로벌 로딩 전략이라고 부릅니다. 페치 조인은 글로벌 로딩 전략 보다 우선시됩니다. 그렇기에 페치 타입을 LAZY로 설정하더라도 페치 조인을 사용하면 데이터가 즉시 조회되는 결과를 가져오게 됩니다. 글로벌 로딩 전략은 될 수 있으면 지연 로딩을 사용하고 최적화가 필요하면 페치 조인을 적용하는 것이 효과적입니다.
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적입니다. 만약 여러 테이블을 조인해서 엔티티가 가진 그대로의 모양이 아닌 다른 결과를 내야 한다면, 페치 조인보다는 일반 조인을 사용하고 필요한 데이터만 조회해서 DTO로 반환하는 것이 효과적입니다.
한계
페치 조인 대상에는 별칭을 줄 수 없기에 SELECT, WHERE, 서브 쿼리에 페치 조인 대상을 사용할 수 없습니다. 이러한 제약을 둔 이유는 잘못된 별칭 사용으로 인해 데이터 무결성이 깨질 수 있으므로 제약을 걸어두었습니다. JPA 표준에서는 지원하지 않지만 하이버네이트를 포함한 몇몇 구현체들은 별칭을 지원합니다. 하지만 위와 같은 문제로 인해 조심해서 사용할 수 있도록 해야 합니다.
앞서 보았던 데이터가 증폭되는 문제로 인하여 둘 이상의 컬렉션을 페치할 수 없습니다. 컬렉션 * 컬렉션의 카테시안 곱이 만들어지므로 가능한 구현체에서도 주의해서 사용해야 합니다.
컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없습니다. 일대일, 다대일과 같은 단일값 연관 필드는 페이징 API를 사용할 수 있습니다. 하이버네이트에서 사용하게 되면 경고 로그를 남기고 모든 데이터를 불러와 메모리에서 페이징을 진행하기 때문에 매우 위험한 작업입니다.
'Spring > Spring Data' 카테고리의 다른 글
| [Error] 엔티티 인식 에러 해결 (0) | 2022.07.29 |
|---|---|
| [JPA] 프록시와 로딩 전략 (0) | 2022.07.20 |
| JPA 연관관계 매핑 정리 (0) | 2022.07.13 |
| 영속성 컨텍스트 (0) | 2022.07.05 |